Talk for Vector Institute
Pathwise Conditioning and
Non-Euclidean
Gaussian Processes

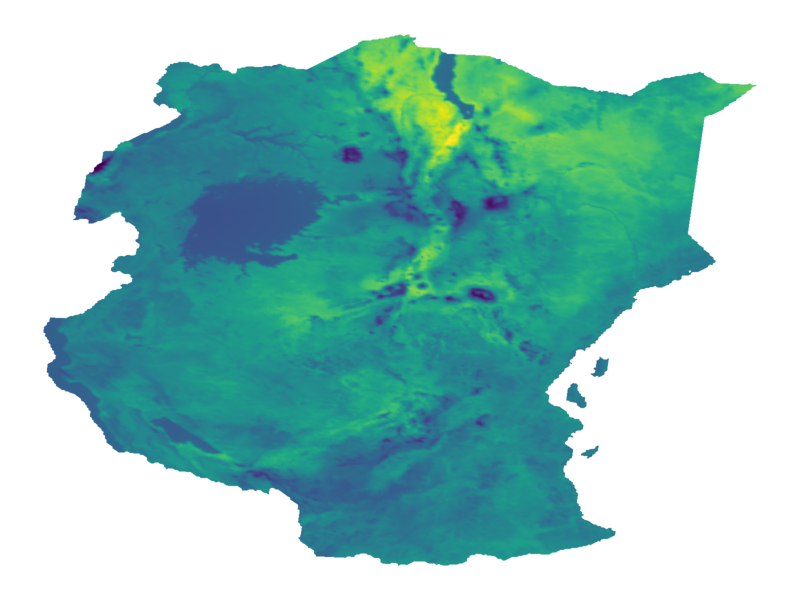
Goal: minimize unknown function $\phi$ in as few evaluations as possible.
Where to gather data: automatic explore-exploit tradeoff.




$$ \htmlData{fragment-index=0,class=fragment}{ x_0 } \qquad \htmlData{fragment-index=1,class=fragment}{ x_1 = x_0 + f(x_0)\Delta t } \qquad \htmlData{fragment-index=2,class=fragment}{ x_2 = x_1 + f(x_1)\Delta t } \qquad \htmlData{fragment-index=3,class=fragment}{ .. } $$

$$ (\v\theta,\v{y}) \~\f{N}(\v\mu,\m\Sigma) $$

$$ (\v\theta\given\v{y}=\v\gamma) \~\f{N}(\v\mu_{\v\theta\given\v{y}}, \m\Sigma_{\v\theta\given\v{y}}) $$
$$ \begin{aligned} \v\mu_{\v\theta\given\v{y}} &= \v\mu_{\v\theta} + \m\Sigma_{\v\theta\v{y}}\m\Sigma_{\v{y}\v{y}}^{-1}(\v\gamma-\v\mu_{\v{y}}) & \m\Sigma_{\v\theta\given\v{y}} &= \m\Sigma_{\v\theta\v\theta} - \m\Sigma_{\v\theta\v{y}}\m\Sigma_{\v{y}\v{y}}^{-1}\m\Sigma_{\v{y}\v\theta} \end{aligned} $$

$$ (\v\theta,\v{y}) \~\f{N}(\v\mu,\m\Sigma) $$

$$ (\v\theta\given\v{y}=\v\gamma) = \v\theta + \m\Sigma_{\v\theta\v{y}}\m\Sigma_{\v{y}\v{y}}^{-1}(\v\gamma-\v\mu_{\v{y}}) $$
$$ \htmlData{class=fragment,fragment-index=2} { (f\given y)(\.) = } \htmlData{class=fragment,fragment-index=0} { \mathrlap{f(\.)} } \htmlData{class=fragment,fragment-index=3} { \ubr{\phantom{f(\.)}}{\c{O}(N_*^3)} } \htmlData{class=fragment,fragment-index=1} { + \m{K}_{(\.)\v{x}} } \htmlData{class=fragment,fragment-index=1} { \mathrlap{\m{K}_{\v{x}\v{x}}^{-1}} } \htmlData{class=fragment,fragment-index=3} { \ubr{\phantom{\m{K}_{\v{x}\v{x}}^{-1}}}{\c{O}(N^3)} } \htmlData{class=fragment,fragment-index=1} { (\v{y} - f(\v{x})) } $$
$$ \htmlData{class=fragment,fragment-index=0}{ (f\given y)(\.) } \htmlData{class=fragment,fragment-index=1}{ \approx \sum_{i=1}^L w_i \phi_i(\.) } \htmlData{class=fragment,fragment-index=4}{ \mathllap{\ubr{\vphantom{\sum_{j=1}^m}\phantom{\sum_{i=1}^\ell w_i \phi_i(\.)}}{\t{RFF prior approx.}}} } \htmlData{class=fragment,fragment-index=2}{ + \sum_{j=1}^N v_j k(\.,x_j) } \quad \phantom{\v{v} = \m{K}_{\v{x}\v{x}}^{-1}(\v{u} - \m\Phi^T\v{w})} \htmlData{class=fragment fade-out d-print-none,fragment-index=6}{ \htmlData{class=fragment,fragment-index=3}{ \mathllap{\v{v} = \m{K}_{\v{x}\v{x}}^{-1}(\v{u} - \m\Phi^T\v{w})} } } \htmlData{class=fragment,fragment-index=6}{ \mathllap{\begin{gathered} \vphantom{} \\[-2ex] \c{O}(N_*)\,\t{complexity} \\[-0.5ex] \smash{\t{in num. test points}} \end{gathered}} } $$



$$ (f\given\v{y})(\.) = f(\.) + \sum_{i=1}^N v_i^{(\v{y})} k(x_i,\.) \vphantom{\sum_{j=1}^M v_j^{(\v{u})} k(z_j,\.)} $$ Exact Gaussian process: $\c{O}(N^3)$

$$ (f\given\v{y})(\.) \approx f(\.) + \sum_{j=1}^M v_j^{(\v{u})} k(z_j,\.) $$ Sparse Gaussian process: $\c{O}(NM^2)$
$$ \begin{gathered} (f\given\v{y})(\.) \approx f(\.) + \sum_{j=1}^M v_j^{(\v{u})} k(z_j,\.) \\ \htmlClass{fragment}{ \v{v}^{(\v{u})} = \m{K}_{\v{z}\v{z}}^{-1}(\v{u} - f(\v{z})) } \qquad \htmlClass{fragment}{ \v{u} \~\f{N}(\v{m},\m{S}) } \end{gathered} $$

$\nu = 1/2$

$\nu = 3/2$

$\nu = 5/2$

$\nu = \infty$
$$
\htmlData{class=fragment fade-out,fragment-index=9}{
\footnotesize
\mathclap{
k_\nu(x,x') = \sigma^2 \frac{2^{1-\nu}}{\Gamma(\nu)} \del{\sqrt{2\nu} \frac{\norm{x-x'}}{\kappa}}^\nu K_\nu \del{\sqrt{2\nu} \frac{\norm{x-x'}}{\kappa}}
}
}
\htmlData{class=fragment d-print-none,fragment-index=9}{
\footnotesize
\mathclap{
k_\infty(x,x') = \sigma^2 \exp\del{-\frac{\norm{x-x'}^2}{2\kappa^2}}
}
}
$$
$\sigma^2$: variance
$\kappa$: length scale
$\nu$: smoothness
$\nu\to\infty$: recovers squared exponential kernel


$$ k_\infty^{(d_g)}(x,x') = \sigma^2\exp\del{-\frac{d_g(x,x')^2}{2\kappa^2}} $$
Theorem. (Feragen et al.) Let $M$ be a complete Riemannian manifold without boundary. If $k_\infty^{(d_g)}$ is positive semi-definite for all $\kappa$, then $M$ is isometric to a Euclidean space.
$$
\htmlData{class=fragment,fragment-index=0}{
\underset{\t{Matérn}}{\undergroup{\del{\frac{2\nu}{\kappa^2} - \Delta}^{\frac{\nu}{2}+\frac{d}{4}} f = \c{W}}}
}
\qquad
\htmlData{class=fragment,fragment-index=1}{
\underset{\t{squared exponential}}{\undergroup{\vphantom{\del{\frac{2\nu}{\kappa^2} - \Delta}^{\frac{\nu}{2}+\frac{d}{4}}} e^{-\frac{\kappa^2}{4}\Delta} f = \c{W}}}
}
$$
$\Delta$: Laplacian
$\c{W}$: (rescaled) white noise
$e^{-\frac{\kappa^2}{4}\Delta}$: (rescaled) heat semigroup
$$ k_\nu(x,x') = \frac{\sigma^2}{C_\nu} \sum_{n=0}^\infty \del{\frac{2\nu}{\kappa^2} - \lambda_n}^{\nu-\frac{d}{2}} f_n(x) f_n(x') $$







$$ f : G \to \R $$
$$ f\Big(\smash{\includegraphics[height=2.75em,width=1.5em]{figures/g1.svg}}\Big) \to \R $$
$$ f\Big(\smash{\includegraphics[height=2.75em,width=1.5em]{figures/g2.svg}}\Big) \to \R $$
$$ f\Big(\smash{\includegraphics[height=2.75em,width=1.5em]{figures/g3.svg}}\Big) \to \R $$
$$ \htmlClass{fragment}{ (\m\Delta\v{f})(x) = \sum_{x' \~ x} w_{xx'} (f(x) - f(x')) } $$ $$ \htmlClass{fragment}{ \m\Delta = \m{D} - \m{W} } $$ $\m{D}$: degree matrix $\m{W}$: (weighted) adjacency matrix
$$ \htmlClass{fragment}{ \underset{\t{Matérn}}{\undergroup{\del{\frac{2\nu}{\kappa^2} + \m\Delta}^{\frac{\nu}{2}} \v{f} = \c{W}\mathrlap{\hspace*{-2.42ex}\c{W}\hspace*{-2.42ex}\c{W}}}} } \qquad \htmlClass{fragment}{ \underset{\t{squared exponential}}{\undergroup{\vphantom{\del{\frac{2\nu}{\kappa^2} - \m\Delta}^{\frac{\nu}{2}+\frac{d}{4}}} e^{\frac{\kappa^2}{4}\m\Delta} \v{f} = \c{W}\mathrlap{\hspace*{-2.42ex}\c{W}\hspace*{-2.42ex}\c{W}}}} } $$ $\m\Delta$: graph Laplacian $\c{W}\mathrlap{\hspace*{-2.42ex}\c{W}\hspace*{-2.42ex}\c{W}}$: standard Gaussian
$$ \htmlClass{fragment}{ \underset{\t{Matérn}}{\undergroup{\vphantom{\v{f} \~\f{N}\del{\v{0},e^{-\frac{\kappa^2}{4}\m\Delta}}} \v{f} \~\f{N}\del{\v{0},{\textstyle\del{\frac{2\nu}{\kappa^2} + \m\Delta}^{-\nu}}}}} } \qquad \htmlClass{fragment}{ \underset{\t{squared exponential}}{\undergroup{\v{f} \~\f{N}\del{\v{0},e^{-\frac{\kappa^2}{2}\m\Delta}}}} } $$
$$ \htmlClass{fragment}{ k_\nu(x,x') = \frac{\sigma^2}{C_\nu} \sum_{n=1}^{|G|} \del{\frac{2\nu}{\kappa^2} + \lambda_n}^{-\nu} \v{f}_n(x)\v{f}_n(x') } $$ $\lambda_n,\v{f}_n$: eigenvalues and eigenvectors of graph Laplacian

















$ \large\x\, $



$ \large\x\, $

$ \large= $









J. T. Wilson,* V. Borovitskiy,* P. Mostowsky,* A. Terenin,* M. P. Deisenroth. Efficiently Sampling Functions from Gaussian Process Posteriors. International Conference on Machine Learning, 2020. Honorable Mention for Outstanding Paper Award.
J. T. Wilson,* V. Borovitskiy,* P. Mostowsky,* A. Terenin,* M. P. Deisenroth. Pathwise Conditioning of Gaussian Process. Journal of Machine Learning Research, 2021.
V. Borovitskiy,* P. Mostowsky,* A. Terenin,* M. P. Deisenroth. Matérn Gaussian Processes on Riemannian Manifolds. Advances in Neural Information Processing Systems, 2020.
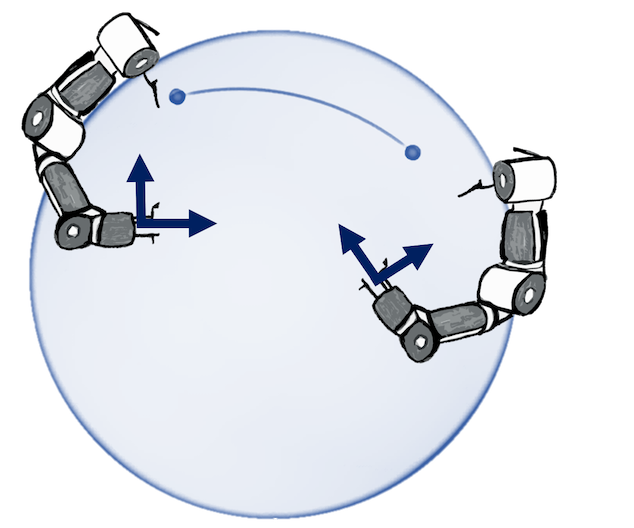
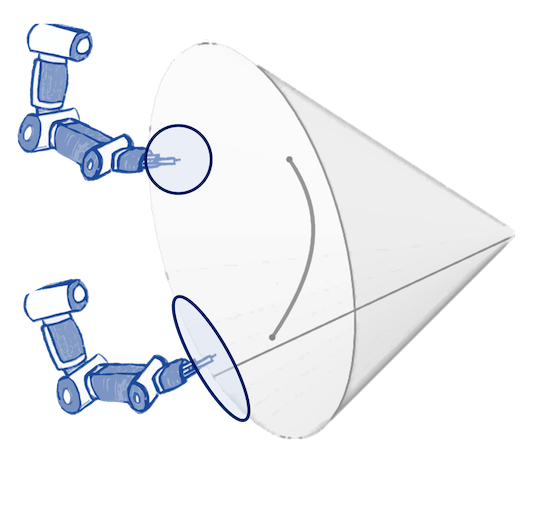
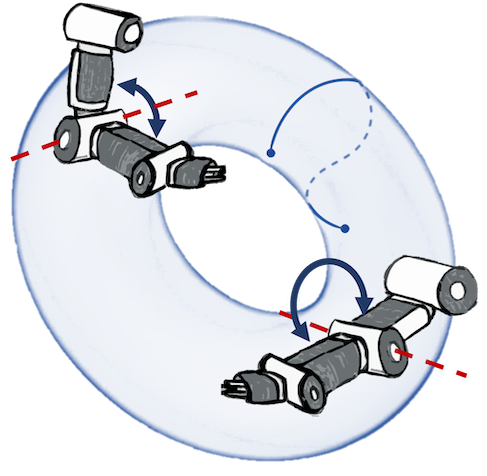
N. Jaquier,* V. Borovitskiy,* A. Smolensky, A. Terenin, T. Asfour, L. Rozo. Geometry-aware Bayesian Optimization in Robotics using Riemannian Matérn Kernels. Conference on Robot Learning, 2021.
V. Borovitskiy,* I. Azangulov,* P. Mostowsky,* A. Terenin,* M. P. Deisenroth, N. Durrande. Matérn Gaussian Processes on Graphs. Artificial Intelligence and Statistics, 2021. Best Student Paper Award.
M. J. Hutchinson,* A. Terenin,* V. Borovitskiy,* S. Takao,* Y. W. Teh, M. P. Deisenroth. Vector-valued Gaussian Processes on Riemannian Manifolds via Gauge Independent Projected Kernels. Advances in Neural Information Processing Systems, 2021.
*Equal contribution