CBL Research Talk, University of Cambridge
Understanding and Scaling Up
Sparse
Gaussian Processes

Goal: minimize unknown function $\phi$ in as few evaluations as possible.
Automatic explore-exploit tradeoff.




$$ \htmlData{fragment-index=0,class=fragment}{ x_0 } \qquad \htmlData{fragment-index=1,class=fragment}{ x_1 = x_0 + f(x_0)\Delta t } \qquad \htmlData{fragment-index=2,class=fragment}{ x_2 = x_1 + f(x_1)\Delta t } \qquad \htmlData{fragment-index=3,class=fragment}{ .. } $$
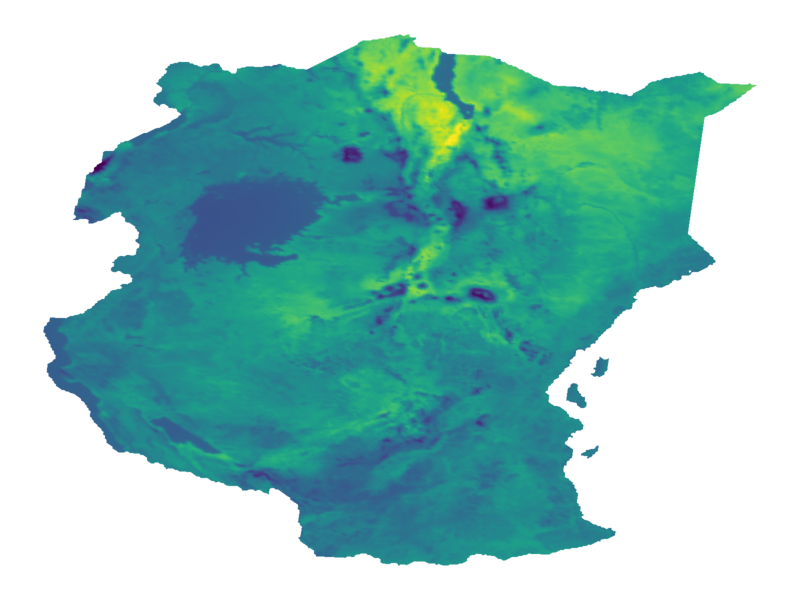







$$ \htmlData{class=fragment,fragment-index=2} { (f\given\v{y})(\.) = } \htmlData{class=fragment,fragment-index=0} { f(\.) } \htmlData{class=fragment,fragment-index=1} { + \m{K}_{(\.)\v{x}} (\m{K}_{\v{x}\v{x}} + \m\Sigma)^{-1} (\v{y} - f(\v{x}) - \v\eps) } $$

$$ (f\given\v{y})(\.) = f(\.) + \sum_{i=1}^N v_i^{(\v{y})} k(x_i,\.) $$

$$ (f\given\v{y})(\.) \approx f(\.) + \sum_{j=1}^M v_j^{(\v{u})} k(z_j,\.) $$
$$ \begin{gathered} (f\given\v{y})(\.) \approx f(\.) + \sum_{j=1}^M v_j^{(\v{u})} k(z_j,\.) \\ \htmlClass{fragment}{ \v{v}^{(\v{u})} = \m{K}_{\v{x}\v{x}}^{-1}(\v{u} - f(\v{x})) } \qquad \htmlClass{fragment}{ \v{u} \~\f{N}(\v{m},\m{S}) } \end{gathered} $$
$$ \htmlClass{fragment}{ \f{cond}(\m{A}) } \htmlClass{fragment}{ = \lim_{\eps\to0} \sup_{\norm{\v\delta} \leq \eps\norm{\v{b}}} \frac{\norm{\m{A}^{-1}(\v{b} + \v\delta) - \m{A}^{-1}\v{b}}_2}{\eps\norm{\m{A}^{-1}\v{b}}_2} } \htmlClass{fragment}{ = \frac{\lambda_{\max}(\m{A})}{\lambda_{\min}(\m{A})} } $$
Result. Let $\m{A}$ be a symmetric positive definite matrix of size $N \x N$, where $N \gt 10$. Assume that $$ \f{cond}(\m{A}) \leq \frac{1}{2^{-t} \x 3.9 N^{3/2}} $$ where $t$ is the length of the floating point mantissa, and that $3N2^{-t} \lt 0.1$. Then floating point Cholesky factorization will succeed, producing a matrix $\m{L}$ satisfying $$ \htmlClass{fragment}{ \m{L}\m{L}^T = \m{A} + \m{E} } \qquad\qquad \htmlClass{fragment}{ \norm{\m{E}}_2 \leq 2^{-t} \x 1.38 N^{3/2} \norm{\m{A}}_2 . } $$
Are kernel matrices always well-conditioned? No.
The Kac–Murdock–Szegö matrix $$ \m{K}_{\v{x}\v{x}} = \scriptsize\begin{pmatrix} 1 & \rho &\rho^2 &\dots & \rho^{n-1} \\ \rho & 1 & \rho & \dots & \rho^{n-2} \\ \vdots & \vdots &\ddots & \ddots & \vdots \\ \rho^{n-1} & \rho^{n-2} & \rho^{n-3} & \dots & 1 \end{pmatrix} $$ satisfies $\frac{1+ 2\rho + 2\rho\eps + \rho^2}{1 - 2\rho - 2\rho\eps + \rho^2} \leq \f{cond}(\m{K}_{\v{x}\v{x}}) \leq \frac{(1+\rho)^2}{(1-\rho)^2}$, where $\eps = \frac{\pi^2}{N+1}$.



Proposition. Assuming spatial decay and stationarity, separation controls $\f{cond}(\m{K}_{\v{z}\v{z}})$ uniformly in $M$.





$$ \htmlData{class=fragment,fragment-index=0}{ \f{cl}(x) = \argmin_{j=1,..,M} \norm{x - z_j} } \qquad \htmlData{class=fragment,fragment-index=2}{ N_{\f{cl}}(x) = |\{x' \in \v{x} : \f{cl}(x) = \f{cl}(x')\}| } $$
$$ \htmlData{class=fragment,fragment-index=0}{ u_j = \frac{1}{N_{\f{cl}}(z_j)}\sum_{\f{cl}(x_i) = z_j} y_i } \qquad \begin{aligned} \htmlData{class=fragment,fragment-index=1}{ y_i \given f } & \htmlData{class=fragment,fragment-index=1}{ \~\f{N}(f(\f{cl}(x_i)),\sigma^2) } \\ \htmlData{class=fragment,fragment-index=2}{ u_i \given f } & \htmlData{class=fragment,fragment-index=2}{ \~\f{N}\del{f(z_i), \tfrac{\sigma^2}{N_{\f{cl}}(z_i)}} } \end{aligned} $$ Then $(f\given\v{u})(\.) = (f\given\v{y})(\.)$ in distribution, and scales with $M \ll N$
$$ \htmlClass{fragment}{ (f\given\v{y})(\.) = f(\.) + \m{K}_{(\.)\v{z}} (\m{K}_{\v{z}\v{z}} + \m\Lambda)^{-1} (\v{u} - f(\v{z}) - \v\epsilon) } \qquad \htmlClass{fragment}{ \v\epsilon \~\f{N}(\v{0},\m\Lambda) } $$


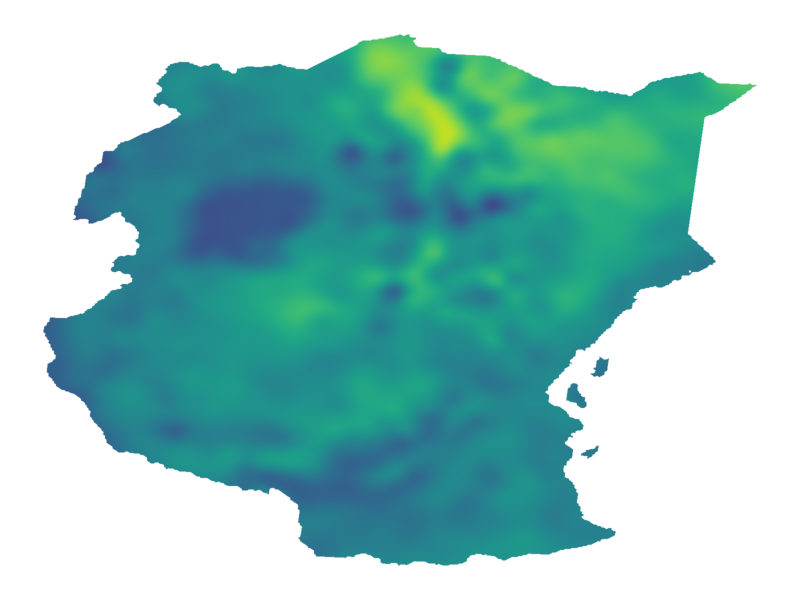

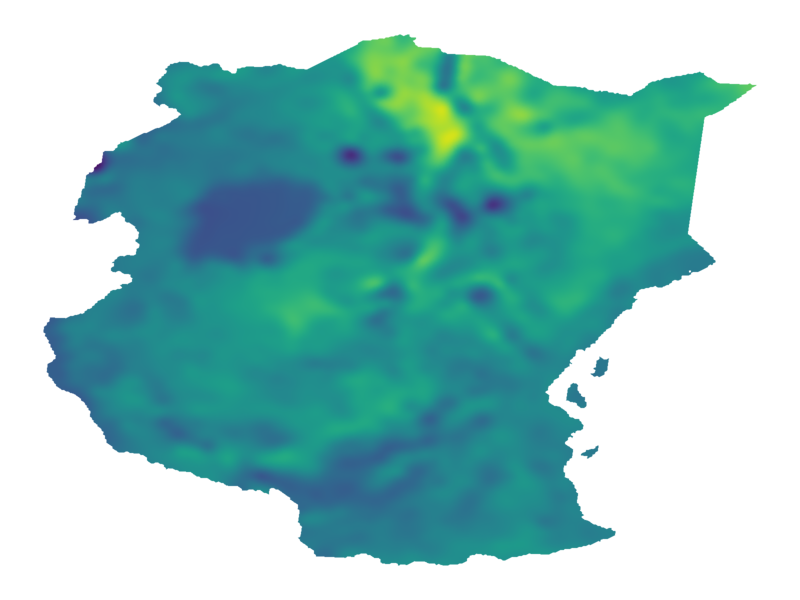

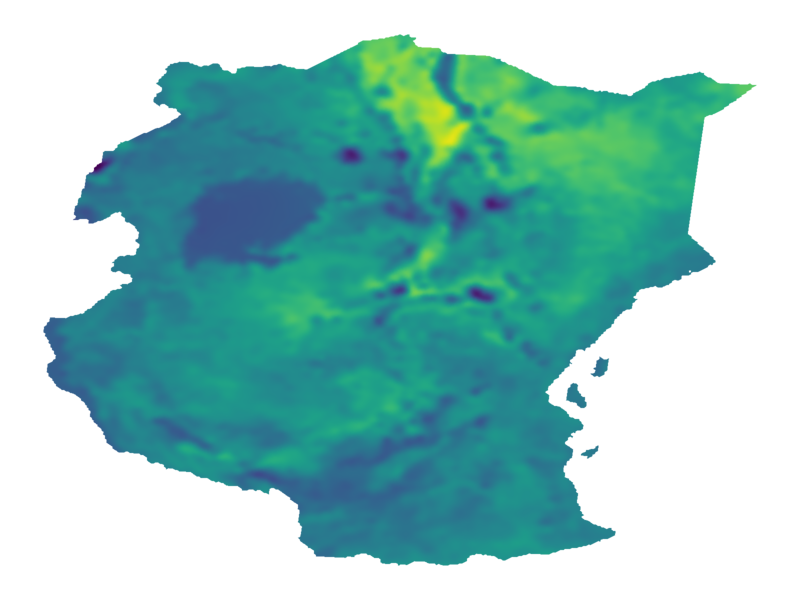


A. Terenin, D. R. Burt, A. Artemev, S. Flaxman, M. van der Wilk, C. E. Rasmussen, H. Ge. Numerically Stable Sparse Gaussian Processes via Minimum Separation using Cover Trees. arXiv: 2210.07893., 2022.